
For SMBs, Redmine serves as the critical backbone of work management, acting as the central nervous system where strategic goals meet daily execution. However, as companies scale and technical operations become more sophisticated, the "vanilla" version often hits functional and stability limits. .
When your project management backbone suddenly goes dark, the impact ripples instantly through your development lifecycle.
We recently surveyed our clients about their biggest pain points regarding Redmine downtime, and the consensus was clear: it’s not just about the server being unreachable. It’s the lost data, the critical time wasted in context switching, and the subsequent project delays that snowball into real financial loss. When your team can’t log hours, update ticket statuses, or push code, the cost of downtime quickly outweighs the cost of professional maintenance.
In this article, we look past the generic "restart your server" advice. We’re diving into the architectural reasons Redmine might hang, how to triage effectively, and how to stop spending your engineering hours on infrastructure maintenance so you can get back to building products.
1. Beyond the surface: why Redmine actually goes down
Unlike SaaS-only alternatives like Asana or Wrike, Redmine’s power—and its primary point of failure—lies in its self-hosted, highly extensible nature. When a CTO sees a downtime event, it usually stems from one of three core areas:
- Database contention: Redmine relies heavily on the underlying database. If you are running complex custom reports, large Gantt chart exports, or heavy SQL-based plugins without proper indexing, the database can hit its connection limit, causing a cascading timeout.
- The "plugin trap": Because Redmine is open-source, the temptation to layer on features is high. However, an incompatible plugin version or a poorly optimized gem can lead to memory leaks in the Ruby on Rails stack, particularly under high concurrent user load.
- Infrastructure mismatch: Running Redmine on an under-provisioned container or failing to manage the Puma/Unicorn worker processes can leave your application unable to handle traffic spikes, especially when automated CI/CD pipelines trigger frequent API requests.
Don't Let Redmine Crash Your Project
Quick fixes, upgrades, and maintenance by certified experts
2. Proactive monitoring: The Zabbix edge
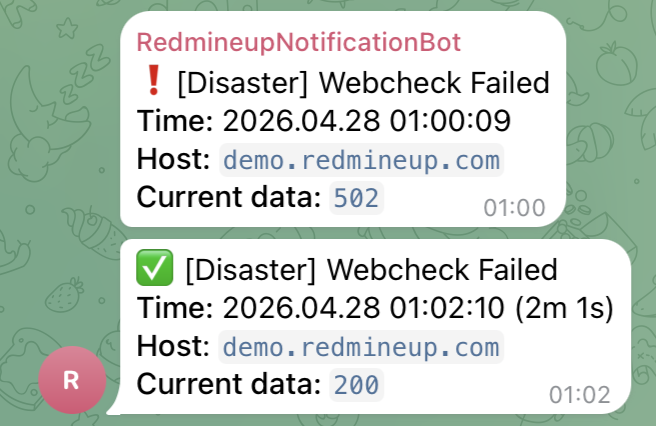
Waiting for a user to report a "500 Internal Server Error" is reactive management. To achieve true resilience, you need observability. Integrating Zabbix into your Redmine infrastructure allows you to move from firefighting to proactive maintenance.
By deploying a Zabbix agent on your Redmine host, you can track critical KPIs that often precede a crash:
- HTTP status codes: Configure a "Web Scenario" in Zabbix to periodically request a non-sensitive page on your Redmine instance. If Zabbix receives a 5xx response, it triggers an immediate alert via Slack, PagerDuty, or Email.
- Process monitoring: Monitor the memory and CPU consumption of your Ruby application servers. A steady climb in memory usage over 24 hours is a classic symptom of a memory leak that can be caught and remediated before the service crashes.
- Database health: Use Zabbix to monitor slow query logs and active database connections. By setting thresholds for connection spikes, your team can investigate potential bottlenecks during high-traffic periods before the database becomes unresponsive.
3. Securing your fortress: top Self-Hosted security integrations
Self-hosting gives you total control over data, but it places the responsibility for security entirely on your team. Redmine has matured significantly in this area; for instance, Redmine 6 now includes native Two-Factor Authentication, removing the need for third-party plugins. To further harden your instance, consider these standard integrations and practices:
- Native 2FA (Redmine 6+): Use the built-in TOTP support for all accounts to mitigate credential theft.
- LDAP/Active Directory: Centralize user authentication and enforce password policies across your company. For cloud-based accounts and teams looking for seamless access, consider our SSO integration to streamline user management.
- SSL/TLS termination: Use Nginx or HAProxy to handle HTTPS encryption, ensuring all traffic between users and Redmine is secure.
- Fail2Ban: Protect your SSH and web login endpoints from brute-force attacks by automatically banning suspicious IPs.
API Token Rotation: Regularly cycle API keys for CI/CD integrations to prevent long-term exposure of service credentials.
4. AI Security procedures: keeping data private

As AI agents become common for task summarization and issue classification, they introduce new attack surfaces. In self-hosted environments, the "gold standard" for AI security is to avoid exposing your data to public, third-party model training.
- Local-first processing: Where possible, leverage local LLM hosting (like Ollama) to process data within your own infrastructure. This ensures proprietary project details never cross your perimeter.
- Permission-aware retrieval: If using RAG (Retrieval-Augmented Generation) to summarize issues, ensure the AI integration layer respects your existing Redmine user permissions. An AI agent should never "know" what a user isn't allowed to see.
- Stateless API interactions: For AI integrations, prefer stateless architectures where API keys are passed per-request (rather than stored server-side) and logs are scrubbed of sensitive PII (Personally Identifiable Information) before being sent to any external processing model.
- GDPR inspector: Before sending any data to an AI model, implement a "GDPR inspector" layer to automatically detect and redact PII such as names, emails, or financial details. This ensures your AI workflows remain fully compliant with data protection regulations, protecting your customers' privacy by design
Just a few weeks ago, we detailed the comprehensive scope of our Redmine upgrade and maintenance process, showcasing how we translate these technical tasks into a hands-off, "set-it-and-forget-it" experience for our clients.
At RedmineUP Hosting, we’ve moved past the "what if" phase of AI. We are actively using these tools to ensure your Redmine instance is faster, more secure, and always available, allowing you to focus entirely on your projects while we handle the complexity of the server.
5. Building your Redmine Recovery Plan
Don't wait for a crash to figure out how to restore your data. As a CTO, you should define a clear recovery strategy. At RedmineUP, we follow a rigorous "Redundancy-First" architecture that you can mirror in your own infrastructure:
- Automated dual-backup: Never rely on a single copy. Schedule daily encrypted dumps of both the database (SQL) and the file repository (/files directory). Store one copy locally for speed and a second in an isolated, off-site cloud storage (like Amazon S3) for disaster scenarios.
- Infrastructure as Code (IaC): Use Docker containers and docker-compose to define your environment. If a server fails, you should be able to spin up a fresh, identical instance by simply pulling your image and mounting your data volumes, rather than manually reconfiguring dependencies.
- Testing recovery (The Drill): A backup is only as good as the last successful restoration. Quarterly, take a backup and restore it to a "sandbox" instance. If you can’t complete the restore in your defined Recovery Time Objective (RTO), your process is still a risk.
- Health checkpoints: Before performing any updates or installing new plugins, always trigger a pre-deployment snapshot. If the new plugin causes a conflict, you should be able to roll back the entire container to the previous state in minutes.
6. Don’t let infrastructure become your full-time job
While understanding the stack is vital, your developers were hired to build your product, not to spend their cycles troubleshooting Gemfile dependencies, managing database migrations, or configuring Zabbix triggers.
Key insights from our infrastructure audits:
- 65% of downtime in self-hosted Redmine environments is caused by preventable configuration drift or unoptimized database queries.
- 40% of page load latency is often linked to "heavy" reporting plugins that lack proper SQL indexing.
- 35% faster feature delivery is reported by teams within the first three months of migrating to our managed hosting, as their engineers shift from "firefighting" to "value-building."
George Baker, BI Analyst
G-Loot We needed to migrate our locally hosted instance of Redmine to the cloud to integrate into our internal tech stack better. Once that became a reality the advantages of using the services of RedmineUP over managing the environment ourselves is immediately apparent. RedmineUP now manages all the administrative tasks like security and backup to leave our internal resources available to concentrate on other more business critical actions.
At RedmineUP, we specialize in the deep technical underpinnings of the platform. We take the burden of maintenance off your plate—handling everything from performance tuning and plugin compatibility audits to urgent troubleshooting—so your team can stay focused on project delivery.
Explore our Redmine Maintenance Services and offload your infrastructure headaches.
The Redmine advantage: stability through expertise
Self-hosting Redmine is a powerful choice for organizations that value data sovereignty and deep customization. Downtime is not an inevitability—it’s a data point. By monitoring your logs, leveraging tools like Zabbix, managing your security features natively, and treating your instance as a production-grade application, you can enjoy the flexibility of Redmine without the fear of the "500 Internal Server Error."
Ready to stop troubleshooting and start shipping? Let our experts handle your instance while you focus on what really matters: your projects.
Don't Let Redmine Crash Your Project
Quick fixes, upgrades, and maintenance by certified experts
